k均值算法
本文共 1525 字,大约阅读时间需要 5 分钟。
K——均值法
一.算法学习:
1.前提:
模式特征矢量集为{x1,x2,…,xN};类的数目K是事先取定的。 2.基本思想: 任意选取K个聚类中心,按最小距离原则将各模式分配到K类的某一类。不断计算聚类中心和调整各模式的类别,最终使各模式到其判属类别中心的距离平方之和最小。 Sj:第j个聚类集(域),Zj ;聚类中心,Nj: Sj中所含的样本个数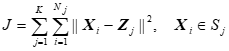
聚类中心的选择应使准则函数J极小,Sj类的聚类中心应选为该类样本的均值。
3.步骤: (1)任选K个模式特征矢量作为初始聚类中心: z1(1) ,z2(1) ,…zK(1)。括号内的序号表示迭代次数。 (2)将待分类的模式特征矢量集{x}中的模式逐个按最小距离原则分划给K类中的某一类。 (3)计算重新分类后的各聚类中心zj(k+1),即求各聚类域中所包含样本的均值向量: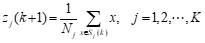 ,以均值向量作新的聚类中心。可得新的准则函数:
,以均值向量作新的聚类中心。可得新的准则函数: 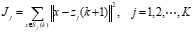
(4)如果zj(k+1)=zj(k)(j=1,2,…K),则结束;否则,k=k+1,转(2)。注意:多次运行K均值算法,例如50~1000次,每次随机选取不同的初始聚类中心。聚类结束后计算准则函数值,选取准则函数值最小的聚类结果为最后的结果。该方法一般适用于聚类数目小于10的情况。
二.例题:
X1(0,0) X2(3,8) X3(2,2) X4(1,1) X5(5,3)
X6(4,8) X7(6,3) X8(5,4) X9(6,4) X10(7,5) 2.1算法分析: 1) 第一个问题应该是选取一个合适的K值,然后随机选取K个点作为初始的聚类中心。 2) 然后就是计算距离,进行聚类(即把点集中每个点分到对应的聚类中)。 3) 计算新的聚类中心,均值法计算。 4) 判断上一轮的聚类中心和本轮的聚类中心是否相等。否则返回第二步。2.2 代码:(python代码经planet B高亮处理)
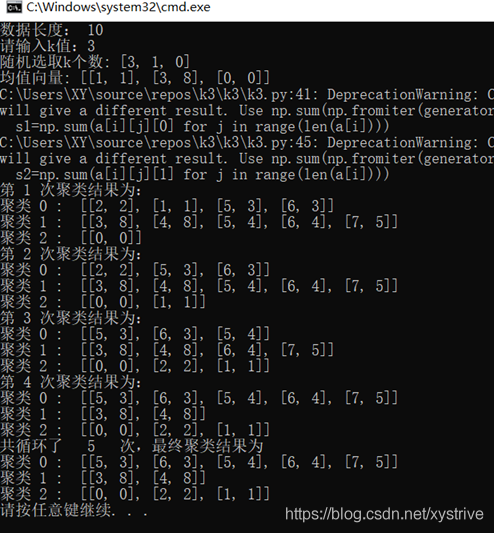
1. import random 2. import numpy as np 3. #数据导入工作 4. data=[[0,0],[3,8],[2,2],[1,1],[5,3],[4,8],[6,3],[5,4],[6,4],[7,5]] 5. l=len(data) 6. print("数据长度:",l) 7. k=int(input("请输入k值:")) 8. #随机选k个向量作为均值向量 9. sj=random.sample(range(l),k) # 10. print("随机选取k个数:",sj) 11. jzxl=[data[i] for i in sj] #均值向量 12. print("均值向量:",jzxl) 13. 14. t=0 15. 16. while True: 17. t=t+1 18. if t>100: 19. print("循环超过100次") 20. break 21. 22. a=[[] for i in range(k)] # k个空列表来存各个样本与均值的距离 23. #计算距离 24. for j in range(l): 25. gds=1000 #固定数作为每轮比较值 26. julei=0 27. for q in range(k): 28. d=np.hypot(data[j][0]-jzxl[q][0],data[j][1]-jzxl[q][1]) 29. if d 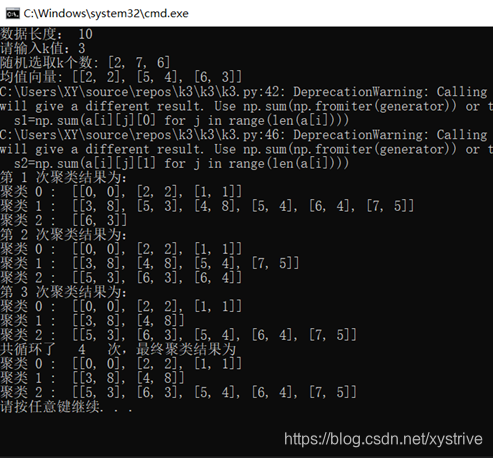
转载地址:http://yqhgz.baihongyu.com/
你可能感兴趣的文章